This Opencv C++ tutorial is about extracting text from an image using Tesseract OCR libraries.
To extract text from an image or to recognise text from an image we need to use Tesseract, which is probably the most accurate OCR engine available.Along with Leptonica image processing it can recognize a wide variety of image formats and extract text details from them an convert it into over 60 languages.
Thus it has immense application likes:
Extracting text from a newspaper/magazine and and digitizing the document thus can be added to further processing like converting it to speech or puting it on web for surfing etc.
Here is the link of downloading tesseract:
http://sourceforge.net/projects/tesseract-ocr/
So steps to configure tesseract with visual studio are:
- Download tesseract library and extract it to a directory( e.g in my it is case D:\)
- Open Visual Studio 2010---New Project--- Visual C++---Windows Console Application
- Click Next---Tick on Empty Project---Finish
- Right Click on Tesseract_ocr and Click Properties.
- Click VC++ directory-- Include Directory---Add
- D:\Tesseract\include
- D:\Tesseract\include\tesseract
- D:\Tesseract\include\leptonica
- Click Library Directories---Add
- Click Linker--Input--Additional Dependencies
- libtesseract302.lib
- libtesseract302d.lib
- liblept168.lib
- liblept168d.lib
- Copy liblept168.dll, liblept168d.dll, libtesseract302.dll and libtesseract302.dll from D:\Arjun\Tesseract\ into your project folder (Optional)
- Copy Tessdata from D:\Arjun\Tesseract-OCR into your project directory.
- Code to check whether its working:





(D:\Arjun\Tesseract\lib)
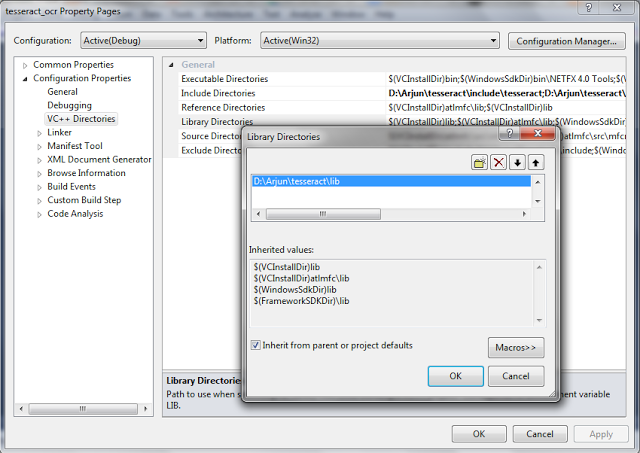
Click OK--Apply

Add this there :
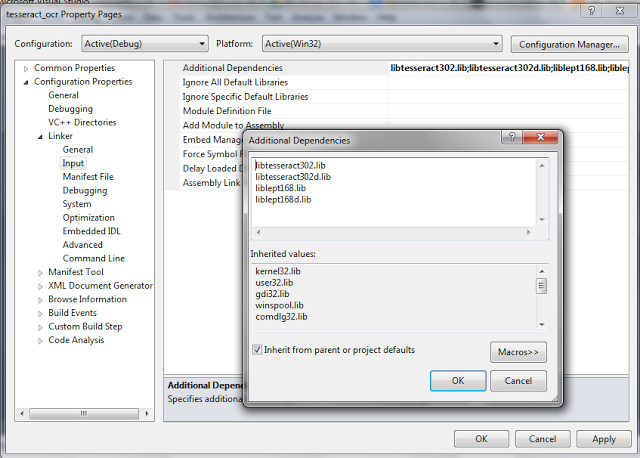
Click Ok--Apply


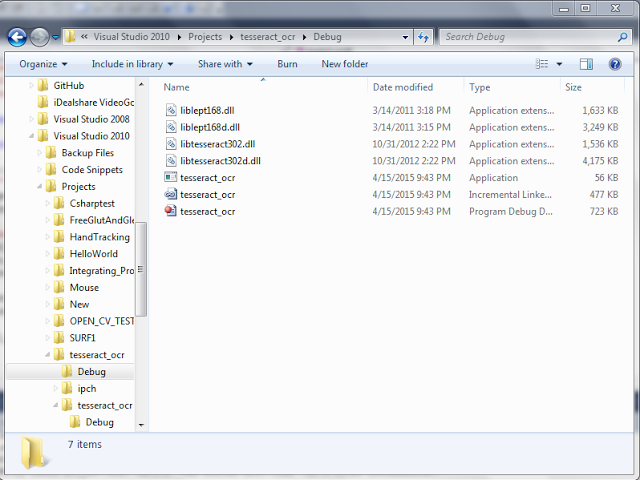
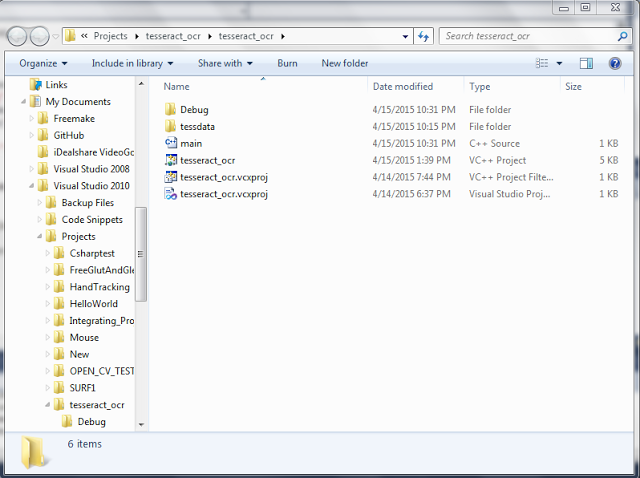
Note: If you miss copying the Tessdata folder into your project directory you will get an error as shown below:
Error opening data file ./tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
File name:

//Opencv C++ Code with example for extracting text from an Image.
//We have used Tesseract OCR Libraries along with OpenCV
#include<baseapi.h>
#include <allheaders.h>
#include <iostream>
using namespace std;
int main(void){
tesseract::TessBaseAPI api;
api.Init("", "eng", tesseract::OEM_DEFAULT);
api.SetPageSegMode(static_cast(3));
api.SetOutputName("out");
cout<<"File name:";
char image[256];
cin>>image;
PIX *pixs = pixRead(image);
STRING text_out;
api.ProcessPages(image, NULL, 0, &text_out);
cout<<text_out.string();
}
Input :

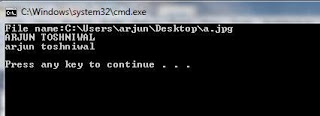
Another Code:
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "tesseract/baseapi.h"
#include "iostream"
using namespace cv;
using namespace std;
int main()
{
// Load image
Mat im = imread("C:\\Users\\arjun\\Desktop\\a.jpg");
if (im.empty())
{
cout<<"Cannot open source image!" <<endl;
return -1;
}
Mat gray;
cvtColor(im, gray, CV_BGR2GRAY);
// ...other image pre-processing here...
// Pass it to Tesseract API
tesseract::TessBaseAPI tess;
tess.Init(NULL, "eng", tesseract::OEM_DEFAULT);
tess.SetPageSegMode(tesseract::PSM_SINGLE_BLOCK);
tess.SetImage((uchar*)gray.data, gray.cols, gray.rows, 1, gray.cols);
// Get the text
char* out = tess.GetUTF8Text();
cout << out <<endl;
return 0;
}
No comments:
Post a Comment